英伟达的软件护城河正在逐渐消失。
随着PyTorch支持更多GPU厂商,再加上OpenAI的Triton搅局,英伟达手中的利器CUDA逐渐锋芒不再。
上述观点来自Semi Analysis首席分析师Dylan Patel,相关文章已引发一波业内关注。

有网友看后评价:
英伟达沦落到此种境地,只因为了眼前利益,放弃创新。

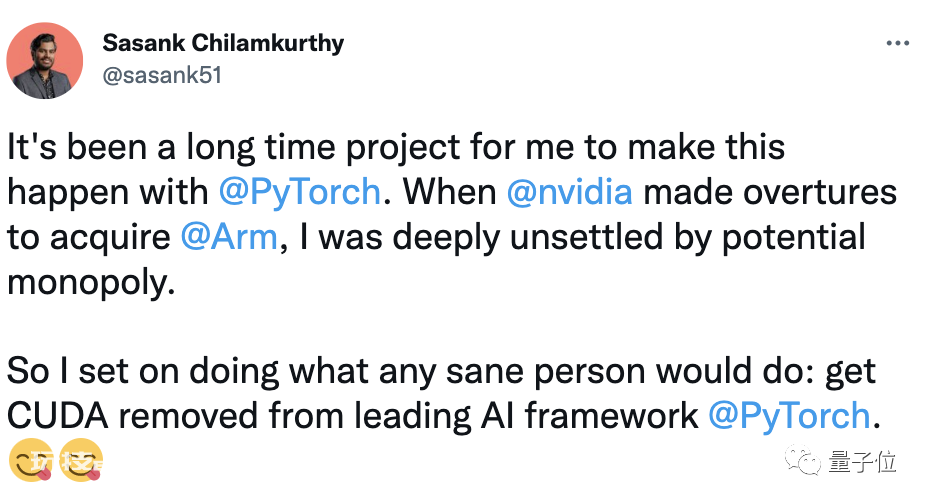
Pytorch的作者之一Sasank Chilamkurthy还补刀:
当英伟达之前提出要收购Arm时,我就对潜在的垄断感到非常不安。所以我开始做任何正常人都会做的事:让CUDA从的领先AI框架中被除名。
下面展开谈一谈Patel提到的这些背后原因。
PyTorch成AI开发框架赢家,将支持更多GPU
这里先来简单说说CUDA昔日的辉煌故事。
CUDA是英伟达推出的并行计算框架。
CUDA之于英伟达,可谓历史的转折点,它的出现,让英伟达在AI芯片领域快速起飞。
在CUDA之前,英伟达的GPU只是一个负责在屏幕上绘制图像的“图形处理单元”。
而CUDA不仅可以调用GPU计算,还可以调用GPU硬件加速,让GPU拥有了解决复杂计算问题的能力,可以帮助客户为不同的任务对处理器进行编程。

除了常见的PC机,无人车、机器人、超级计算机、VR头盔等多种热门的设备都有GPU;而在很长一段时间内,只有英伟达的GPU,才能快速处理各种复杂的AI任务。

那么风光无限的CUDA,后来怎么就地位不稳了?
这还得从AI开发框架之争聊起,尤其是PyTorch VS TensorFlow。
如果把PyTorch这些框架比做车,那CUDA就是变速箱——它可以加速机器学习框架的计算过程,当在英伟达GPU上运行PyTorch等时,可以更快地训练、运行深度学习模型。
TensorFlow发育早,也是谷歌门下利器,但奈何近两年其势头逐渐被PyTorch超越。几大顶会上,PyTorch框架使用的比例也明显上涨:
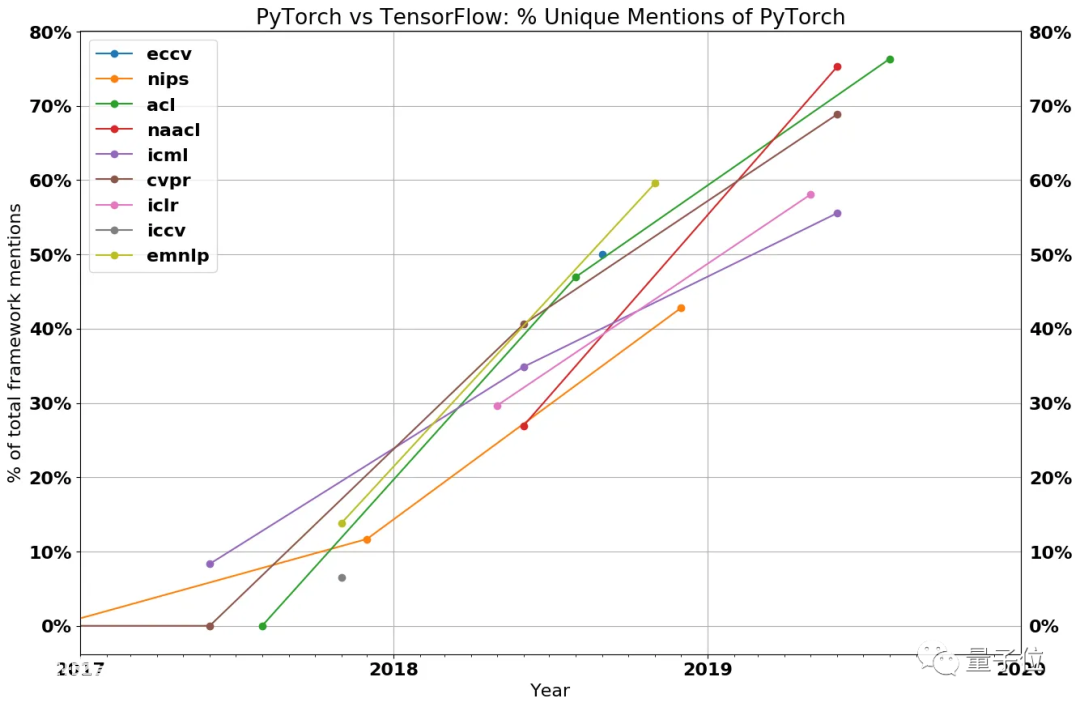
△
还有TensorFlow深度使用者现身说法:“现在我改用PyTorch了。”

PyTorch能胜出,一个关键因素在于它比TensorFlow更灵活易用。
这一方面得益于PyTorch的eager模式,支持在C++运行环境下修改模型,还可以立即看到每一步操作的结果。虽然TensorFlow现在也有eager模式,但大多数大型科技公司已经在围绕着PyTorch开发解决方案。(扎心了……)
另一方面,虽然用这二者都写Python,但用的PyTorch的舒适度更胜一筹。
此外,PyTorch可用的模型更多,生态更丰富,据统计,在HuggingFace中,85%的大模型都是用PyTorch框架实现的。
过去,虽然各大AI开发框架之间打得火热,但更底层的并行计算架构CUDA可算独霸一方。
但时过境迁,在AI框架的角逐中,PyTorch最终赢过此前领跑的TensorFlow,地位暂时稳了,然后就开始搞事情。
近些年PyTorch在拓展支持更多GPU,即将发布的PyTorch2.0首个稳定版也会对其他各家GPU和加速器支持进行完善,包括AMD、英特尔、特斯拉、谷歌、亚马逊、微软、Meta等等。
也就是说,英伟达GPU不再是那个唯一了
不过这背后其实也还有CUDA自身的问题。
内存墙是个问题
前面提到,CUDA崛起与机器学习浪潮彼此促进,共赢生长,但有个现象值得关注:
近些年,领头羊英伟达硬件的FLOPS不断提高,但其内存提升却十分有限。以2018年训练BERT的V100为例,作为最先进GPU,其在FLOPS上增长一个数量级,但内存增加并不多。
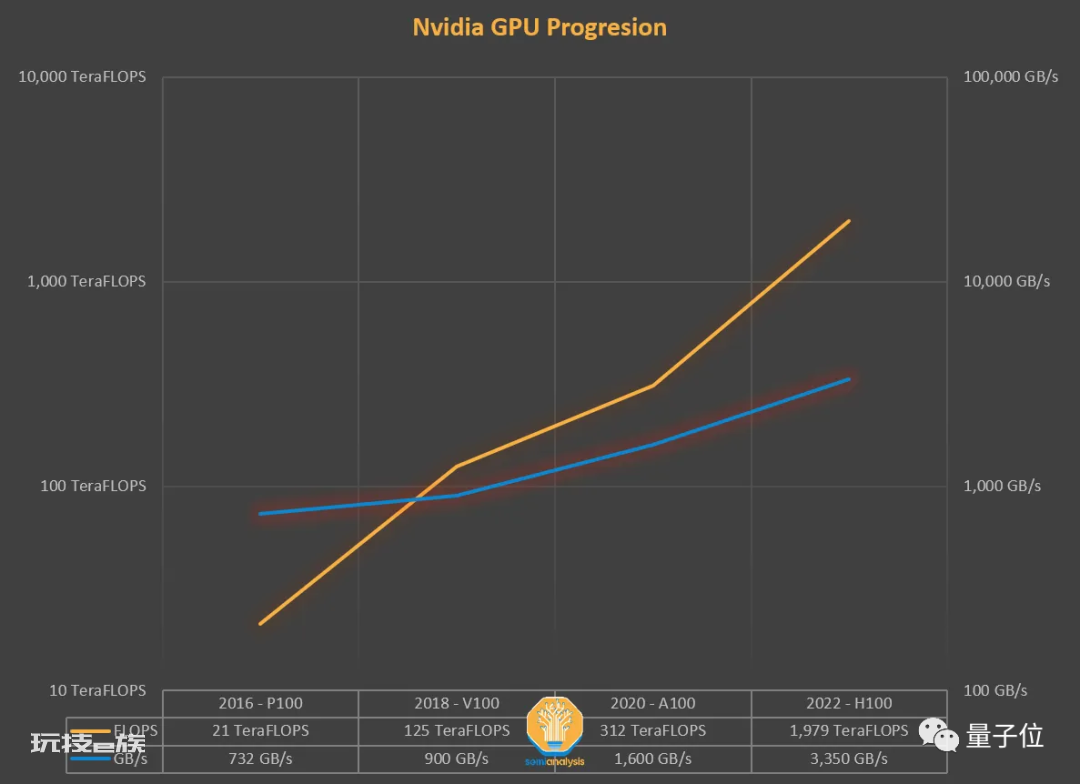
△
在实际AI模型训练中,随着模型越来越大,内存需求也越来越大。
比如百度和Meta,在部署生产推荐网络时,需要数十TB内存来存储海量的embedding table。
放训练及推理中,大量时间实际上并未花在矩阵乘法计算上,而是在等待数据到达计算资源。
那为什么不搞更多内存?
简而言之,钞能力不足。

一般来说,内存系统根据数据使用需求,遵照从“又近又快”到“又慢又便宜”的结构安排资源。通常,最近的共享内存池在同一块芯片上,一般由SRAM构成。
在机器学习中,一些ASIC试图用一个巨大的SRAM来保存模型权重,这种方法遇到动辄100B+的模型权重就不够了。毕竟,即便是价值约500万美元的晶圆级芯片,也只有40GB的SRAM空间。
放英伟达的GPU上,内存就更小了:A100仅40MB,下一代的H100是50MB,要按量产产品价格算,对于一块芯片每GB的SRAM内存成本高达100美元。
账还没算完。目前来说,片上SRAM成本并没随摩尔定律工艺提升而大幅降低,若采用台积电下一代3nm制程工艺,同样的1GB,反而成本更高。
相比SRAM,DRAM倒是成本低很多,但延迟高一个数量级,且2012年来DRAM的成本也几乎没有明显压降。
随着AI继续向前发展,对内存的需求,还会增加,内存墙问题就是这么诞生的。
目前DRAM已占服务器总成本的50%。比如英伟达2016年的P100,比起最新的H100,FB16性能提升46倍,但内存容量只增加了5倍。

△
另一个问题也与内存有关,即带宽。
计算过程中,增加内存带宽是通过并行性获得的,为此,英伟达使用了HBM内存(High Bandwidth Memor),这是一种3D堆叠的DRAM层组成的结构,封装更贵,让经费朴实的使用者们只能干瞪眼。
前面提到,PyTorch的一大优势在于:Eager模式让AI训练推理更灵活易用。但其内存带宽需求量也十分肥硕。
算子融合,即解决上述问题的主要方法。其要义在于“融合”,不将每个中间计算结果写入内存,而是一次传递,计算多个函数,这样就将内存读写量变少。
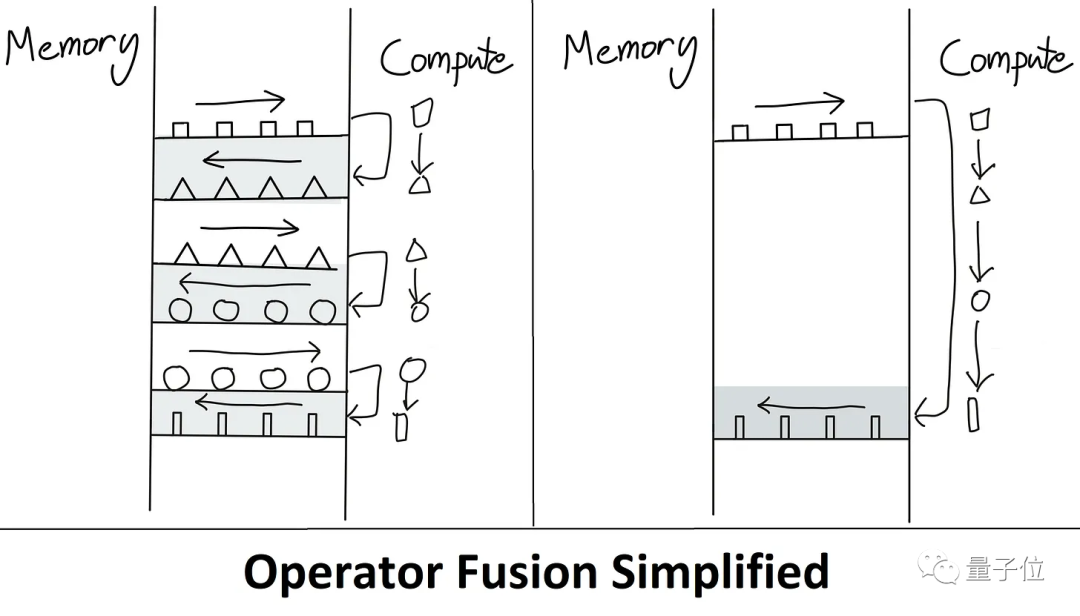
△
要落地“算子融合”,要编写自定义CUDA内核,要用到C++语言。
这时CUDA的劣势就显现出来了:比起写Python脚本,编写CUDA之于很多人真是难太多了……
相比下,PyTorch 2.0工具就能大幅降低这个门槛。其内置英伟达和外部库,无需专门学习CUDA,直接用PyTorch就能增加运算符,对炼丹师们来说,自然友好很多。
当然,这也导致PyTorch在近些年大量增加运算符,一度超过2000个(手动狗头)。
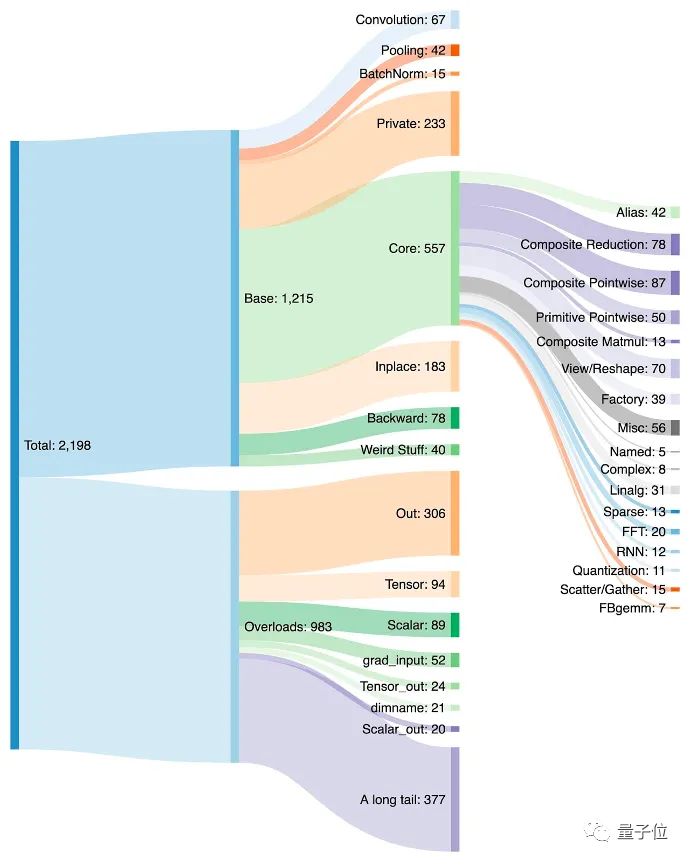
2022年末,刚发布的升级款PyTorch2.0更是大举发力,瞄准编译。
因添加了一个面向图像执行模型的编译解决方案,该框架在A100上训练性能提升86%,CPU推理性能也提升26%。
此外,PyTorch 2.0依靠PrimTorch技术,将原来2000多个算子缩到250个,让更多非英伟达的后端更易于访问;还采用了TorchInductor技术,可为多个加速器和后端自动生成快速代码。
而且PyTorch2.0还能更好支持数据并行、分片、管道并行和张量并行,让分布式训练更丝滑。
正是上述技术,再结合对英伟达之外厂商GPU和加速器的支持,原先CUDA为英伟达构筑的软件城墙就显得没那么高不可攀了。
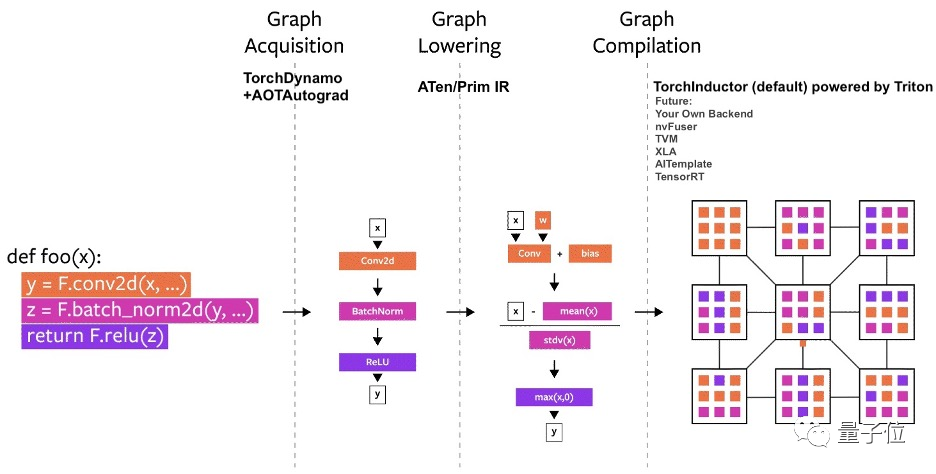
身后还有替代者
这边英伟达自身内存提升速度没跟上,那边还有PyTorch2.0搞事,但还没完——
Open AI推出了个“简化版CUDA”:Triton。(直接偷家)

Tirton是种新的语言和编译器。它的操作难度比CUDA低,但性能却可与后者媲美。
OpenAI声称:
Triton只要25行代码,就能在FP16矩阵乘法shang上达到与cuBLAS相当的性能。
OpenAI的研究人员已经使用Triton,生成了比同等Torch效率高出1倍的内核。
虽然Triton目前只正式支持英伟达GPU,但之后这个架构也会支持多家硬件供应商。
还有值得一提的是,Triton是开源的,比起闭源的CUDA,其他硬件加速器能直接集成到Triton中,大大减少了为新硬件建立AI编译器栈的时间。
不过话说回来,也有人觉得CUDA的垄断地位还远不算被打破。比如PyTorch的另一位作者、Meta杰出工程师Soumith Chintala就觉得:
(分析师Patel写的)这篇文章夸大了现实,CUDA将继续是PyTorch依赖的关键架构。
Tirton并不是第一个(优化)编译器,目前大多数还是把注意力放在XLA编译器上面的。

他表示,现在尚不清楚Tirton是否会慢慢被大家接受,这还得靠时间来验证。总之,Triton并没有对CUDA构成太大威胁。
文章作者Patel本人也看到了这条评论,然后回复称:
我可没说(CUDA的垄断地位)已经没了(Broken),而是说正在退步(Breaking)。
而且目前Triton还只正式支持英伟达GPU(没在别的GPU测试性能),如果XLA在英伟达GPU上的表现不占优势,那它恐怕不如Triton。
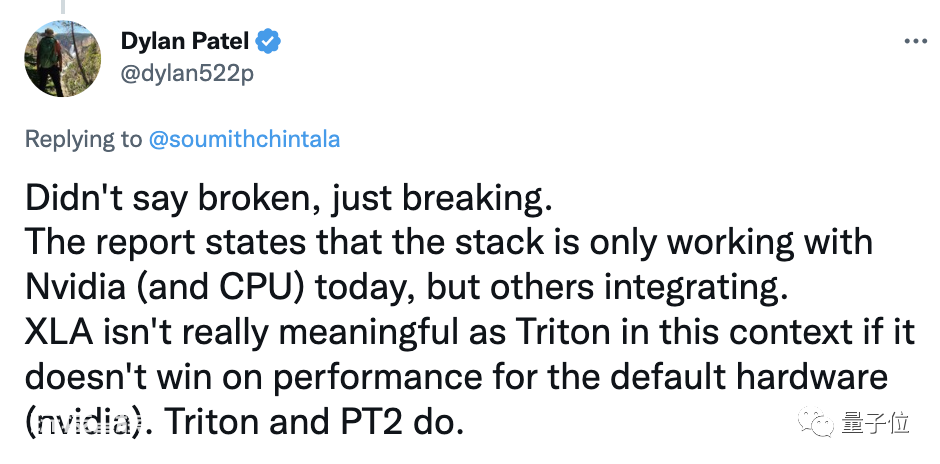
但Soumith Chintala反驳道,就算说CUDA的地位正在下滑也不妥。因为Tirton要在硬件上推广的话,还有很多风险,还有很长的路要走。

有网友和这位PyTorch作者站在同一边:
我也希望垄断被打破,但目前CUDA还是最顶的,没了它,很多人构建的软件和系统根本玩不转。

那么,你觉得现在CUDA境况如何?
参考链接:
[1]https://www.semianalysis.com/p/nvidiaopenaitritonpytorch
[2]https://analyticsindiamag.com/how-is-openais-triton-different-from-nvidia-cuda/
[3]https://pytorch.org/features/
[4]https://news.ycombinator.com/item?id=34398791
[5]https://twitter.com/soumithchintala/status/1615371866503352321
[6]https://twitter.com/sasank51/status/1615065801639489539
本文来自微信公众号“量子位”(ID:QbitAI),作者:詹士 Alex。