


近日,Nature子刊发表Meta最新研究成果,揭示目前的语言模型与人类大脑的差异,或将为开发更强大的生成式AI提供启示。
1000亿个神经元,每个神经元有8000个左右的突触,大脑的复杂结构为人工智能研究带来启发。
当前,多数深度学习模型的架构,便是一种受生物大脑神经元启发的人工神经网络。

生成式AI大爆发,可以看到深度学习算法在生成、总结、翻译和分类文本的能力越来越强大。
然而,这些语言模型仍然无法与人类的语言能力相匹配。
恰恰预测编码理论(Predictive coding)为这种差异提供了一个初步的解释:
虽然语言模型可以预测附近的词,但人脑会不断预测跨越多个时间尺度的表征层次。
为了验证这一假设,Meta AI的科学家分析了304位听完短篇故事的人的大脑功能磁共振成像信号。
得出结论是,分层预测编码在语言处理中发挥至关重要的作用。
与此同时,研究说明了神经科学和人工智能之间的协同作用如何能够揭示人类认知的计算基础。
最新研究已发表在Nature子刊Nature Human Behavior上。

论文地址:https://www.nature.com/articles/s41562-022-01516-2
值得一提的是,实验过程中用上了GPT-2,说不定未来这一研究能够启发到OpenAI未开源的模型。
到时候ChatGPT岂不是更强了。

大脑预测编码分层
不到3年的时间,深度学习在文本生成、翻译等方面取得重大进展,要归功于一个训练有素的算法:根据附近语境预测单词。
值得注意的是,这些模型的激活已被证明可以线性地映射到大脑对语音和文字的反应上。
此外,这种映射主要取决于算法预测未来单词的能力,因此表明这一目标足以使它们收敛到类似大脑的计算。
然而,这些算法和大脑之间仍然存在着差距:尽管有大量的训练数据,但目前的语言模型在长篇故事生成、总结和连贯对话以及信息检索方面遇到挑战。
因算法无法捕捉一些句法结构和语义属性,而且对语言的理解也很肤浅。
比如,算法倾向于将动词错误地分配给嵌套短语中的主语。
「the keys that the man holds ARE here」
同样,当文本生成只针对下一个词的预测进行优化时,深度语言模型会生成平淡无奇、不连贯的序列,或者会陷入无限重复的循环中。
当前,预测编码理论为这一缺陷提供了一个潜在的解释:
虽然深层语言模型主要是为了预测下一个词,但这个框架表明,人脑可以在多个时间尺度和皮层层次的表征上进行预测。

此前研究已经证明了大脑中的语音预测,即一个词或音素,与功能磁共振成像(fMRI),脑电图,脑磁图和皮质电图相关联。
为预测下一个单词或音素而训练的模型,可以将其输出简化为一个数字,即下一个符号的概率。
然而,预测表征的性质和时间范围在很大程度上是未知的。

在这项研究中,研究人员提取了304个人的fMRI信号,让每个人听约26分钟的短篇小说 (Y) ,并且输入相同内容激活语言算法 (X)。
然后,通过「大脑分数」量化X和Y之间的相似性,即最佳线性映射W后的皮尔逊相关系数(R)。
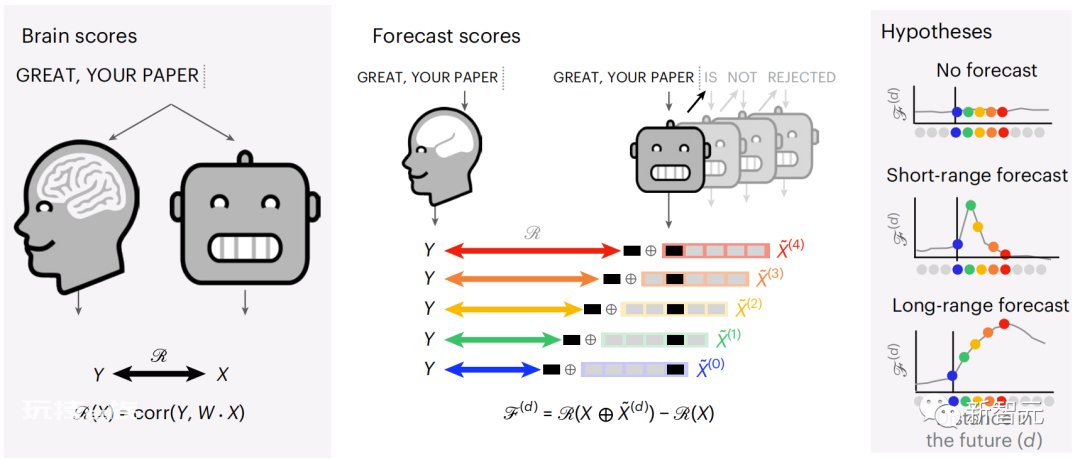
为了测试添加预测单词的表示是否改善了这种相关性,将网络的激活 (黑色矩形 X) 连接到预测窗口 (彩色矩形~X) ,再使用PCA将预测窗口的维数降低到X的维数。
最后F量化了通过通过增强语言算法对该预测窗口的激活而获得的大脑得分增益。我们用不同的距离窗口重复这个分析(d)。
通过用跨越多个时间尺度的预测,即远距离预测和分层预测,来增强这些算法,发现可以改善这种大脑映射。
最后,实验结果发现这些预测是分层组织的:额叶皮层比颞叶皮层预测更高层次、更大范围和更多的上下文表征。

实验结果
深度语言模型映射到大脑活动中
科研人员定量了研究输入内容相同时深度语言模型和大脑之间的相似性。
使用Narratives数据集,分析了304个听短故事的人的fMRI(功能性磁共振成像)。
对每个体素和每个实验个体的结果进行独立的线性岭回归,以预测由几个深度语言模型激活而得到的fMRI信号。
使用保留的数据计算了相应的 「大脑分数」,即fMRI信号和输入指定语言模型刺激所得的岭回归预测结果之间的相关性。
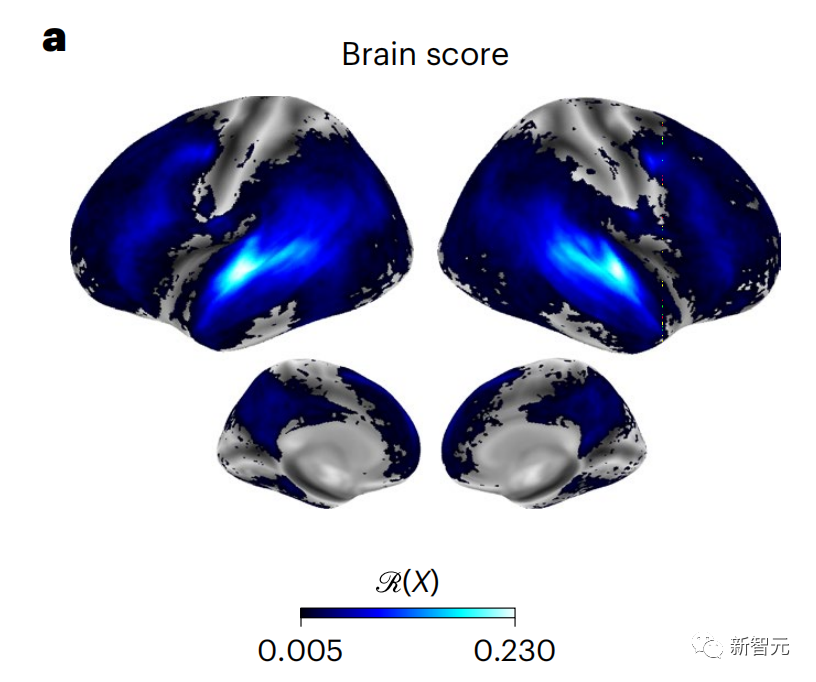
为清晰起见,首先关注GPT-2第八层的激活,这是一个由HuggingFace2提供的12层因果深度神经网络,最能预测大脑活动。
与以前的研究一致,GPT-2的激活结果准确地映射到一组分布式双边大脑区域,大脑分数在听觉皮层和前颞区和上颞区达到高峰。
大脑中的长距离预测
Meta团队接着测试了增强对具有长距离预测功能的语言模型的刺激是否能使其获得更高的大脑分数。
对于每个词,研究人员将当前词的模型激活和一个由未来词组成「预测窗口」连接起来。预测窗口的表示参数包括表示当前词和窗口中最后一个未来词之间距离的d和所串联词数量的w。对于每个d,比较有和没有预测表征时的大脑分数,计算「预测分数」。
结果显示,d=8时预测分数最高,峰值出现在与语言处理有关的大脑区域。

d=8对应于3.15秒的音频,即两个连续的fMRI扫描的时间。预测分数在大脑中呈双边分布,除了额叶下部和边缘上回。
通过补充分析,团队还得到如下结果:(1)与当前词距离0到10的每个未来词都对预测结果有明显贡献;(2)预测表征最好用8个左右的词的窗口大小来捕捉;(3)随机预测表征不能提高大脑得分;(4)比起真正的未来词,GPT-2生成的词能够取得类似的结果,但得分较低。
预测的时间范围沿着大脑的层次发生变化
解剖学和功能学研究都表明,大脑皮层分层次的。不同层次的皮层,预测的时间窗口是否相同呢?
研究人员估计了每个体素预测分数的峰值,将其对应的距离表示为d。
结果显示,前额叶区的预测峰值出现时对应的d平均而言要大于颞叶区(图2e),颞下回的d就要大于颞上沟。

最佳预测距离沿颞-顶-额轴的变化在大脑两个半球上基本是对称的。
句法和语义预测的时间范围不同
对于每个词及其前文语境,生成十个可能的未来词,这与真正未来词的句法相匹配。对于每个可能的未来词,提取相应的GPT-2激活并取其平均值。这种方法能够将给定语言模型激活分解为句法成分和语义成分,从而计算其各自的预测分数。

结果显示,语义预测是长距离的(d = 8),涉及一个分布式网络,在额叶和顶叶达到峰值,而句法预测的范围较短(d = 5),集中在上颞区和左额区。


这些结果揭示了大脑中多层次的预测,其中上颞皮层主要预测短期、浅层和句法表征,而下额叶和顶叶区域主要预测长期、上下文、高层和语义表征。
预测的背景沿着大脑层次变得更复杂
仍按照之前的方法计算预测分数,但改变了GPT-2的使用层,为每个体素确定k,即预测分数最大化的深度。
我们的结果表明,最佳预测深度沿着预期的皮质层次而变化,联想皮层比低级语言区有更深的预测的最佳模型。区域之间的差异虽然平均很小,但在不同的个体中是非常明显的。

总的来说,额叶皮层的长程预测比低水平脑区的短期预测背景更复杂,水平更高。
将GPT-2调整为预测性编码结构
将GPT-2的当前词和未来词的表征串联起来可以得到更好的大脑活动模型,特别是在额叶区。
对GPT-2进行微调以预测距离更远、背景更丰富、层次更高的表征,能否改善这些区域的大脑映射呢?
在调整中,不仅使用了语言建模,还使用了高层次和长距离的目标,这里的高层次目标是预训练的GPT-2模型的第8层。
结果显示,用高层次和远距离建模对进行GPT-2微调最能改善额叶的反应,而听觉区和较低层次的脑区并没有从这种高层次的目标中明显受益,进一步反映了额叶区在预测语言的长程、语境和高层次表征方面的作用。

参考资料
https://www.nature.com/articles/s41562-022-01516-2
本文来自微信公众号“新智元”(ID:AI_era),作者:Ellie 桃子。



















